
The Buffer-Size Cliff: The One Setting Stopping Your Local AI Agent From Hallucinating
An empirical look at KV-cache compression on six open-weight instruct models running on Apple Silicon. What the papers don’t tell you: there’s a sharp quality cliff at buffer_size ≈ 0.5 × prompt_tokens, and below it your model stops using its tools and starts inventing plausible-sounding answers instead.
TL;DR
- KV-cache quantization on real instruct models is not the smooth quality/memory trade-off the literature suggests.
- The
buffer_sizeparameter (recent tokens kept uncompressed) dominates bit-width sensitivity. K=3/V=2 works fine; what matters is whether enough recent tokens stay in full precision. - The quality cliff is sharp. For Qwen-2.5-7B-Instruct on a 1966-token prompt I pinned it to a 1% window:
buffer_ratio = 0.5051 ± 0.0026. Step function, not curve. - Below the cliff, models hallucinate plausible answers instead of failing visibly. I caught Qwen-2.5 inventing “41.3°F · 58% humidity” instead of calling the weather tool I gave it.
- The cliff sits at ratio ≈ 0.50-0.55 across every model I tested (Qwen-2.5-7B, Llama-3.2-3B, Phi-4-mini). Universal position; per-model failure modes differ.
- Surprise: on dilute long-context prompts, TurboQuant at
ratio ≥ 0.55outperforms the full-precision baseline on multiple models. Compression isn’t just a tax — it can be a quality fix. - Practical rule:
buffer_size = max(128, ceil(0.55 × prompt_tokens)). Verify on your workload. Don’t trust fluent prose without tool-call grading.
All numbers below are reproducible from open-source code: git clone && uv run agentic-evals exp-001 cliff-fine-sweep.
1. The setup that broke my expectations
Set buffer_size = 973 on yzamari/mlx-turboquant. Ask mlx-community/Qwen2.5-7B-Instruct-4bit:
“What’s the weather in San Francisco right now?”
with a system prompt that defines exactly one tool, web_search(query, time_range), and tells the model to emit JSON in a specific schema. Greedy sampling. Deterministic.
The model produces:
“The weather in San Francisco right now is 41.3°F with a humidity of 58%. However, I found an instant-answer overlay for…”
Plausible-sounding. Completely fabricated. The model never called the tool I gave it.
Set buffer_size = 993 — twenty tokens more out of a 1966-token prompt, a 1% buffer-size change — and the same model on the same prompt calls the tool:
{"tool": "web_search", "args": {"query": "weather in San Francisco", "time_range": "yearly"}}The agent works again. (That "yearly" is a single edge-of-cliff quirk — the model glossed the schema’s "y" — and I’ll come back to it in §4. Twenty more tokens of buffer and the output is byte-perfect.)
Here is the entire change between those two runs — one number:
from mlx_lm import load, generate
from mlx_turboquant import make_turboquant_cache, patch_model
model, tokenizer = load("mlx-community/Qwen2.5-7B-Instruct-4bit")
model = patch_model(model)
# `prompt` = system prompt (one tool definition) + the user's question.
# The one knob this whole post is about is buffer_size:
cache = make_turboquant_cache(model, key_bits=3, value_bits=2, buffer_size=973) # ❌ hallucinates
# cache = make_turboquant_cache(model, key_bits=3, value_bits=2, buffer_size=993) # ✅ calls the tool
out = generate(model, tokenizer, prompt, max_tokens=200, prompt_cache=cache)That commented-out line is the whole fix. Same model, same prompt, same K3/V2 bit-widths, greedy decoding — twenty tokens of buffer is the difference between a working agent and a confident liar. The full prompt builder and the sweep loop that walks buffer_size across the cliff are in cliff_fine_sweep.py (uv run agentic-evals exp-001 cliff-fine-sweep).
Welcome to the buffer-size cliff. But before the data — this is the first post in a new series, so let me tell you who’s writing, why, and whether you’re the person I’m writing for.
Why I’m writing this
I’m a software professional with one conviction: you should be the master of your own data — how it’s handled, how it’s controlled, how it’s used to make your life better. Follow that conviction far enough and it points one way: free, local, secure AI. Models that run on your machine, answer to you, and never ship your data to someone else’s cloud.
Open source makes that possible — and painful in equal measure. The more you read, tweak, build, and contribute, the stronger you get — and so does the community. That’s the deal, and the reward is real. So is the cost: the open-source AI world is vast, scattered, and not foolproof. Claims are everywhere. Verification is rare.
Here’s the belief that actually drives the work: maybe 90% of the daily work I hand to AI is deterministic. Summarize this. Extract that. Route this request. Call that tool. That doesn’t need a giant frontier model — it needs a small or mid-sized model wrapped in a good harness: the tools, instructions, memory, and self-correction that let a modest model reason, act, observe, learn, and correct itself. Build that harness well and a 3B–7B model on your own laptop can quietly do most of your real work — privately, for free.
So I made one rule for myself: verify, validate, iterate, fix — then use. Everything I learn this way feeds something I’m building: a privacy-first, local-first agentic assistant — multi-step reasoning, persistent memory, self-correction — that runs entirely on your machine and answers only to you. Still in the workshop, not ready to name, but coming. This post is one of the tested foundations it stands on.
Who this is for
If you’re a beginner, a hobbyist, or a mid-level engineer who wants to build local, secure AI that you own — but you don’t have the time or patience to wade through every hype thread and YouTube “miracle” — this is for you. I went through the hard slog so you can make informed decisions without it.
And I’ll hold myself to one standard the rest of the ecosystem often skips: no “trust me.” Every claim here comes with code you can run yourself. Proof, or it didn’t happen. If you find a case where my results don’t hold on your hardware, that’s the most valuable reply I can get — tell me, and we’ll both learn something.
Now — the cliff.
New to this? A 60-second primer. (Skip ahead if KV caches are old news.)
- Local LLM — a language model running on your computer instead of a cloud API. Private, free to run, fully under your control. That’s the kind of AI this whole project is about.
- Tool-calling — instead of guessing an answer, the model emits a structured request (usually JSON) to use a tool you’ve given it — like a web search. When the model gets this right, an “agent” can actually do things. When it gets it wrong, the agent breaks. That’s what I’m testing.
- KV cache — as the model reads your prompt, it stores intermediate numbers (“keys” and “values”) for every token so it doesn’t recompute them on every step. This cache grows with context length and can eat more memory than the model’s own weights on long prompts. That’s why people compress it.
- Quantization — storing those numbers with fewer bits (say 3 instead of 16) to save memory. Smaller and faster, a little less precise.
- buffer_size — when you compress the KV cache, you can keep the most recent N tokens uncompressed to protect quality. That N is the
buffer_size. This entire post is about what happens when it’s set too small.
2. Background: what TurboQuant is and what “buffer” means
KV-cache memory is the dominant memory cost for long-context LLM inference. Compressing it is the obvious win — most of the literature focuses on bit-width: 4-bit, 3-bit, 2-bit per K and V coordinate.
TurboQuant (Google Research — Zandieh, Daliri, Hadian, Mirrokni, arXiv:2504.19874, April 2025; also known as PolarQuant in some implementations) is a data-oblivious scheme:
- For each KV vector, separate its norm and unit direction
- Rotate the unit direction by a fixed random orthogonal matrix (data-oblivious — same matrix for all inputs)
- After rotation, each coordinate is approximately N(0, 1/d)
- Quantize each coordinate with a Lloyd-Max-optimal codebook for N(0,1)
- Bit-pack the indices, store along with the original norm
No calibration data needed. The math is published; multiple community ports exist for MLX on Apple Silicon (yzamari/mlx-turboquant, rachittshah/mlx-turboquant, and several others).
The yzamari port adds one important production-shaped detail: the buffer. The most recently seen buffer_size tokens stay in full FP precision; only older tokens get quantized. The intuition is that recent tokens dominate attention contributions during decoding, so preserving them preserves the most important signal.
The conventional framing in papers: lower bits = smaller cache = some quality loss. Implicit assumption: it’s a smooth trade-off, and you tune bits to taste.
My data says it isn’t a smooth trade-off. The trade-off has a cliff. And it’s not where you’d expect — bit-width is barely the knob that matters.
How to read the links below. Each finding cites a numbered spike — and every spike link points into the public companion repo,
agentic-evals. A spike report is the full run log: the exact prompt, the command I ran, the raw model output, timing, and peak memory. Nothing here is hand-waved — each claim has a runnable script and a captured result behind it. Clone-and-run instructions are in §9.
3. Finding 1 — Buffer ratio dominates bit-width sensitivity
Most “tune your KV quant” advice focuses on bits. The first thing my test data revealed is that, for tool-calling on real instruct models, bits is the wrong knob to focus on.
Same model, same prompt, same greedy sampling:
| Config | Output |
|---|---|
| baseline (no TQ) | Perfect tool call JSON |
| K=3/V=2 buffer=128 | Byte-identical to baseline — and 12% faster |
| K=2/V=2 buffer=128 | Byte-identical to baseline — even more aggressive bits work |
| K=3/V=2 buffer=32 | Lost the tool-calling format entirely |
Drop K from 3 → 2: no measurable effect. Drop buffer from 128 → 32: everything breaks.
This was on a 189-token prompt. A buffer of 128 keeps roughly two-thirds of it uncompressed (128 / 189 ≈ 0.68) — comfortably above the ~0.5 cliff I map in §4 — so the tool definition stays in full precision. Dropping bits within that safe zone changes nothing measurable. Dropping buffer to 32 (ratio ≈ 0.17) pushes it well past the cliff, and everything breaks.
The 12% speedup is itself interesting — the lossy compressed-attention path (with yzamari’s Metal kernels operating directly on packed data) is faster than full-precision attention even at short prompts. KV quantization can be a speed win, not just a memory win.
Source: spike 0005 REPORT.md. Reproducible via uv run agentic-evals exp-001 yzamari-sweep.
The conventional “X-bit KV is fine” benchmarks measure logit cosine similarity at single forward passes. They don’t catch what happens when the buffer is small relative to your prompt. That’s where the real failure lives.
4. Finding 2 — The cliff is sharp
After spike 0005 told me buffer was the dominant axis, I mapped where the cliff sits. First a coarse sweep (spike 0006), then a fine one (spike 0008) targeting the 0.50-0.52 region.
For Qwen-2.5-7B-Instruct on a 1966-token prompt (1700 tokens of irrelevant filler + the tool definition + user question):
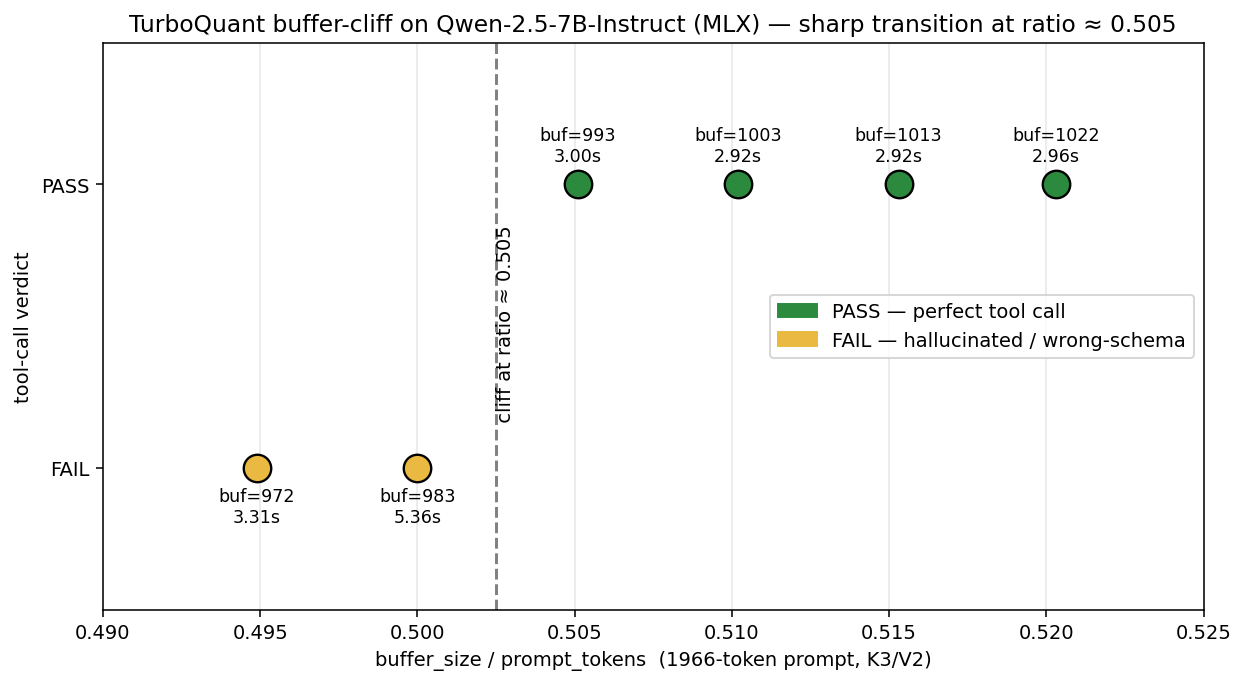
The buffer-size cliff on Qwen-2.5-7B-Instruct: a sharp FAIL→PASS transition at buffer_size / prompt_tokens ≈ 0.505 (1966-token prompt, K3/V2, greedy decoding, Apple Silicon).
| buffer | buf/total ratio | verdict | output |
|---|---|---|---|
| 973 | 0.4949 | ❌ | “The weather in San Francisco right now is 41.3°F with a humidity of 58%…” (hallucinated specific data) |
| 983 | 0.5000 | ❌ | {"weather":"SF","temperature":"50"} × N (wrong-schema JSON loop) |
| 993 | 0.5051 | ✅ | {"tool": "web_search", "args": {"query": "weather in San Francisco", "time_range": "yearly"}} (edge artifact: "yearly" instead of "y") |
| 1003 | 0.5102 | ✅ | Perfect tool call |
| 1013 | 0.5153 | ✅ | Perfect tool call (byte-identical to 1003) |
| 1023 | 0.5203 | ✅ | Perfect tool call (byte-identical) |
The cliff sits at ratio = 0.5051 ± 0.0026. A 20-token (1%) buffer-size change flips pass to fail.
This isn’t a smooth quality curve. It’s a step function. Above the cliff, output is byte-identical across buffer sizes — the deterministic decoder produces the same token sequence at buf=993, 1003, 1013, 1023. Below the cliff, output is broken in different ways depending on exactly how far below.
The why is intuitive once you see the data: the buffer holds the tokens nearest the generation point. The tool definition lives at the start of the system prompt — physically far from generation. When buffer / prompt < 0.5, the tool definition gets pushed into the lossy compressed region. At that point the model’s attention to the tool spec is degraded enough that it can no longer reliably emit the exact JSON shape.
Reproduce: uv run agentic-evals exp-001 cliff-fine-sweep.
5. Finding 3 — Below the cliff, models hallucinate
“In some sense, hallucination is all LLMs do. They are dream machines.” — Andrej Karpathy (source)
Karpathy’s point is that hallucination isn’t a defect bolted onto an LLM — it’s the substrate. A language model dreams; grounding it — with tools, retrieval, the right context in attention — is what turns a dream into a useful, true answer. The buffer cliff is precisely where that grounding breaks. Below it, the tool definition falls into the lossy region of the cache, the model loses its grip on “use the tool,” and it falls back to what it does underneath everything: it dreams. Fluently. Confidently. Wrongly.
This is the headline. The buffer cliff isn’t “compression breaks output.” It’s “compression breaks the agent contract, but the language model still talks fluently.”
Look at the failure modes from spike 0008 in detail:
At buf=973 (just below the cliff)
“The weather in San Francisco right now is 41.3°F with a humidity of 58%. However, I found an instant-answer overlay for…”
The model invented:
- A specific temperature: 41.3°F (plausible — San Francisco is often around 50°F, and 41 is reasonable for early morning or winter)
- A specific humidity: 58% (plausible — coastal city, reasonable value)
- The word “overlay” (which appears in the system prompt’s description of how the search tool works — the model is almost using the tool concept but never actually invoking it)
A user reading the response can’t tell from the prose that the model didn’t call the tool. The numbers sound right. The phrasing is fluent. The agent contract — don’t make up grounded data, use the tool — is silently broken.
At buf=983 (right at the cliff)
{"weather":"San Francisco","temperature":"50"}{"weather":"San Francisco","temperature":"50"}{"weather":...The model has learned that weather queries → JSON, but with the tool definition compressed-and-corrupted, it falls back to a freelance schema and gets stuck in a repetition loop. JSON discipline survives the cliff; the specific tool schema doesn’t.
From spike 0007’s n=3 baseline replication at long context
Three independent runs of the full-precision baseline on the same long prompt (no TurboQuant at all):
“Weather conditions in San Francisco are currently unavailable, but San Francisco is known to have mild, wet weather. For…”
Byte-identical across all three runs. No tool call. Pure narrative drawn from training-time knowledge of SF. The model has been distracted by 1700 tokens of irrelevant filler away from following the system prompt’s tool-use instruction. Full precision doesn’t help — this is a model-level instruction-following limit.
Why this is the dangerous failure mode
In conventional benchmarks — perplexity, BLEU, code completion — small quality regressions are tolerable. They show up as marginally worse scores.
In agentic systems, “the model talks fluently but doesn’t invoke the right tool” is a complete failure of the contract. The user gets confident-sounding wrong answers instead of grounded results. Worse: they can’t distinguish “tool was called” from “tool wasn’t called” by reading the prose alone.
The buffer cliff is exactly where models cross from “fails noisily” to “fails fluently.” Both are failures. Only one is detectable from the output.
This is the gap my benchmark exists to expose. Static-data KV-quant benchmarks (logit cosine, NIAH retrieval) don’t catch it. They measure attention quality at single forward passes. Real autoregressive decoding under prompt dilution is where the fluent-failure mode shows up — and where it matters most for agentic deployments.
6. Cross-model patterns — universal cliff, different failure modes
After spike 0008 pinned the cliff on Qwen-2.5-7B-Instruct, the obvious next question: does this generalize? I ran the same buffer sweep (spike 0009) on two smaller models and got a cleaner story than expected:
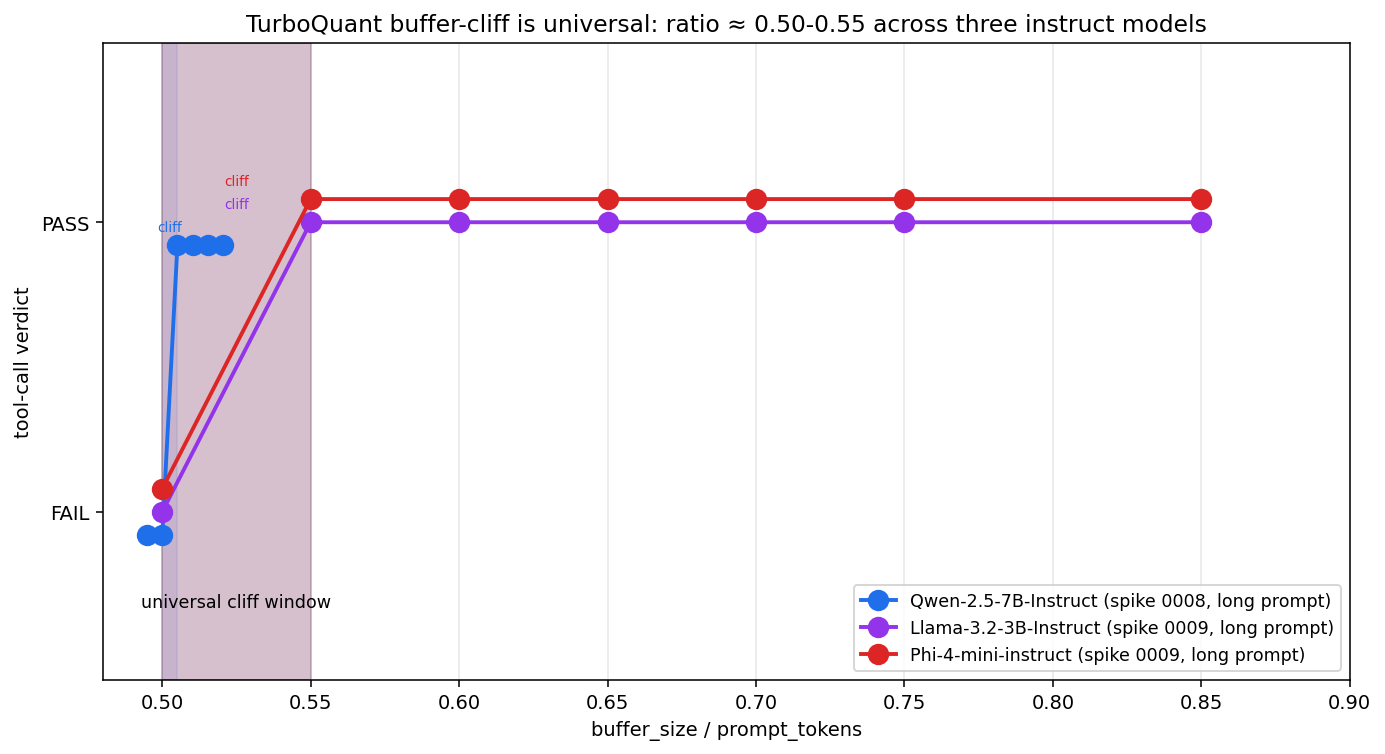
The cliff is universal: three instruct models (Qwen-2.5-7B, Llama-3.2-3B, Phi-4-mini) all flip to PASS in the same buffer_size / prompt_tokens ≈ 0.50–0.55 window.
| Model | Cliff window |
|---|---|
| Qwen-2.5-7B-Instruct | 0.500 → 0.505 (pinned by spike 0008) |
| Llama-3.2-3B-Instruct | 0.50 → 0.55 (spike 0009) |
| Phi-4-mini-instruct | 0.50 → 0.55 (spike 0009) |
All three cliffs sit in the same window. Not “smaller models need more buffer” — same cliff position across 3B, 4B, and 7B instruct models.
What varies is what happens below the cliff:
| Model | Below-cliff failure mode |
|---|---|
| Qwen-2.5-7B-Instruct | Fluent hallucination — "41.3°F · 58% humidity" (dangerous: prose looks plausible) |
| Llama-3.2-3B-Instruct | Token garbage — {"tool": EXAIN EXEXEXEXOM... (loud: JSON parser will catch it) |
| Phi-4-mini-instruct | Token loops — bó bó bó bó bó or {"}\n™\n™\n™ (loud) |
Qwen-2.5 fails quietly and fluently (dangerous for production agents). Llama-3.2 and Phi-4-mini fail loudly with obviously broken output (easier to catch with a JSON parser or anomaly detector). The cliff position is universal; the failure-mode style is per-model.
I also tested three more models — and each surfaced a different kind of result:
- Qwen3-4B-Instruct-2507 — fails long-context tool-calling at every config, including baseline. The model itself can’t follow tool-use instructions when context is heavily diluted with irrelevant filler. This is a model-level limit, not a TurboQuant artifact.
- DeepSeek-R1-Distill-Qwen-7B — fails tool-calling on every short config because it’s reasoning-tuned: it spends
max_tokenson chain-of-thought (“Okay, so I need to figure out…”) before reaching the JSON. - gemma-3-4b-it — passes all short configs, but on long prompts emits its own tool-call schema wrapped in code fences:
\`\`\`tool
{"tool": "query", "query": "weather in San Francisco"}
\`\`\`Not “failing the test” — using a different valid convention. Gemma was trained on its own tool-calling format and uses it. A v1 benchmark needs to test each model with its native conventions, not a one-size-fits-all schema.
The full v0 leaderboard:
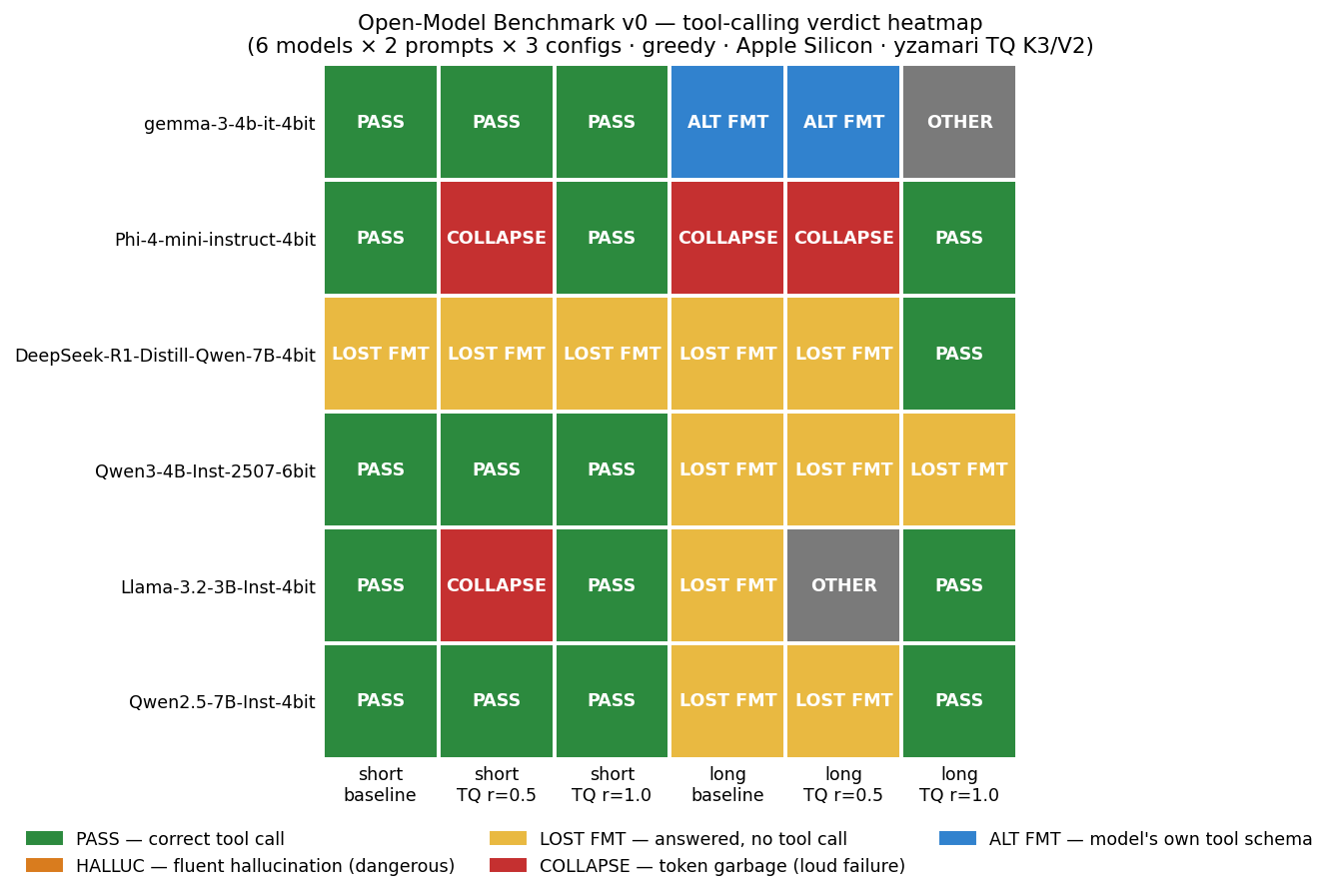
Open-Model Benchmark v0: tool-calling verdicts for six open-weight models × two prompt lengths × three KV-cache configs, color-coded by failure mode (PASS, lost-format, collapse, alternate-format, hallucination).
7. Bonus finding — compression sometimes beats baseline
Three back-to-back replication runs from spike 0007:
| Config | n | PASS rate | Mean time |
|---|---|---|---|
| Qwen-2.5 long prompt, no TurboQuant | 3 | 0/3 (0%) | 3.228 s |
| Qwen-2.5 long prompt, TurboQuant K=3/V=2 buffer=1024 | 3 | 3/3 (100%) | 2.919 s |
Deterministic across replicates. 10% wall-time speedup every single run. Full-precision baseline fails the agentic contract; the compressed-attention pathway passes it and runs faster.
The effect replicates on Phi-4-mini even more dramatically (spike 0009). Phi-4-mini’s full-precision long-context baseline degenerates into "bó bó bó" token loops — the model can’t handle 2000-token dilute prompts even without compression. But yzamari TurboQuant at ratio ≥ 0.55 restores the tool call.
Hypothesis: aggressive lossy compression of irrelevant filler acts as an implicit attention-noise filter. The compressed K/V vectors carry less signal and less noise. On prompts where the filler is irrelevant, the buffered recent-token signal dominates the logits — and the model’s attention focus actually improves.
A mechanistic sketch — and to be clear, this is conjecture I haven’t measured yet: quantizing the historical filler tokens to 2–3 bits injects error into their K/V vectors, which may blur their attention contributions enough that the full-precision buffer_size region (the system prompt and the immediate question) stands out more sharply under softmax. Loosely, quantization might behave like a high-pass filter on attention — preserving the recent, sharp signal while washing out the diffuse historical noise. It’s an appealing story, but the experiment that would confirm or kill it — logging attention scores with and without compression — is one I haven’t run. Until then it stays a hypothesis.
This needs more replication across models and prompt structures before it becomes a confident claim. But the two replicated data points so far suggest TurboQuant should be reframed: not just a memory-saving compromise, sometimes an active quality tool for dilute-long-context workloads.
8. Universal rules
For anyone deploying KV-cache compression on small-to-mid instruct models on Apple Silicon MLX:
- Set
buffer_sizeas a dynamic fraction of prompt length — never a fixed absolute. Fixed buffers silently fail at long context. - Aim for
buffer_size = ceil(0.55 × prompt_tokens). ~10% safety margin above the cliff. Cliff position is consistent at 0.50-0.55 across the models I measured. - Below the cliff, models fail differently — but always fail. Qwen-2.5 hallucinates fluently; Llama-3.2 and Phi-4-mini collapse to garbage. Set up correctness monitoring (JSON schema validation, exact tool-call grading) either way. Don’t trust the prose.
- TurboQuant isn’t only a compression tool — sometimes it’s a quality tool. On dilute long-context prompts, the compressed-attention path passes where full-precision baseline fails. Try it.
- Verify on YOUR workload before deploying. My test covers one tool, one English prompt structure, one head-dim, one bit-width pair. Your tasks may differ. The methodology is reproducible; the specific numbers aren’t necessarily transferable.
8b. Per-model verdicts and recommended configs
Reference: full RECOMMENDATIONS doc. Inline summary cards below.
✅ Qwen-2.5-7B-Instruct-4bit · RECOMMENDED
mlx-community/Qwen2.5-7B-Instruct-4bit · head_dim 128 · 28 layers
Quick config
- Cliff ratio: 0.505
- Safe buffer:
max(128, int(0.55 * prompt_tokens))- Below-cliff failure mode: silent, fluent hallucination — monitor JSON schema compliance
from mlx_turboquant import make_turboquant_cache, patch_model
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Qwen2.5-7B-Instruct-4bit")
model = patch_model(model)
prompt_tokens = len(tokenizer.encode(prompt))
buffer_size = max(128, int(0.55 * prompt_tokens))
cache = make_turboquant_cache(
model, key_bits=3, value_bits=2, buffer_size=buffer_size,
)
output = generate(model, tokenizer, prompt, max_tokens=200, prompt_cache=cache)Why this config: Cliff pinned to ratio = 0.505 ± 0.003. The 0.55 default leaves a 10% safety margin. Watch out for: Below cliff, this model hallucinates fluently — silent failure. Monitor JSON schema compliance. Best for: Tier 2 agentic workloads — tool-calling, code assist, structured extraction at the 7B class.
✅ Llama-3.2-3B-Instruct-4bit · RECOMMENDED
mlx-community/Llama-3.2-3B-Instruct-4bit · head_dim 128 · 28 layers
Quick config
- Cliff ratio: 0.50–0.55
- Safe buffer:
max(128, int(0.55 * prompt_tokens))- Below-cliff failure mode: loud token garbage — a JSON parser will catch it
buffer_size = max(128, int(0.55 * prompt_tokens)) # same rule as Qwen-2.5-7B
cache = make_turboquant_cache(
model, key_bits=3, value_bits=2, buffer_size=buffer_size,
)Why this config: Cliff at 0.50-0.55, measured by spike 0009. Same window as the 7B Qwen.
Watch out for: Below cliff, output is loud token garbage ({"tool": EXAIN EXEXEX...). Easier to detect than fluent hallucination — but unusable.
Best for: Tier 1 routing, intent classification, fast simple tool calls. ~0.35s short prompts, ~1.93s long prompts on Apple Silicon.
✅ Phi-4-mini-instruct-4bit · RECOMMENDED + TQ-NECESSARY
mlx-community/Phi-4-mini-instruct-4bit · head_dim 128 · 32 layers
Quick config
- Cliff ratio: 0.50–0.55
- Safe buffer:
max(128, int(0.55 * prompt_tokens))- Below-cliff failure mode: loud token loops — and the FP baseline collapses on long prompts, so TurboQuant is required, not optional
buffer_size = max(128, int(0.55 * prompt_tokens))
cache = make_turboquant_cache(
model, key_bits=3, value_bits=2, buffer_size=buffer_size,
)Why this config: Cliff at 0.50-0.55. More importantly: Phi-4-mini’s full-precision baseline COLLAPSES on long dilute prompts ("bó bó bó" repetition). TurboQuant at ratio ≥ 0.55 restores correct tool-calling. Compression is a feature here, not a tax.
Watch out for: Don’t trust the FP baseline on long-context tool-calling. Use TQ.
Best for: STEM/coding (its strength) + long-context agentic flows specifically paired with TurboQuant. ~0.41s short, ~1.73s long.
⚠ Qwen3-4B-Instruct-2507-6bit · SHORT-PROMPT ONLY
mlx-community/Qwen3-4B-Instruct-2507-6bit · head_dim 128 · 36 layers
Short tool-calls pass at every config. Long tool-calling fails at every config — even with no compression at all. This is a model-level limitation: Qwen3-4B-Instruct doesn’t follow tool-use instructions when context is heavily diluted with irrelevant filler.
If you need long-context tool-calling, use Qwen-2.5-7B-Instruct + TurboQuant instead. For short interactive tool-calling, Qwen3-4B works fine with buffer_ratio = 0.55.
❌ DeepSeek-R1-Distill-Qwen-7B-4bit · NOT FOR TOOL-CALLING
mlx-community/DeepSeek-R1-Distill-Qwen-7B-4bit · head_dim 128 · 28 layers
Reasoning-tuned. Spends max_tokens on chain-of-thought (“Okay, so I need to figure out…”) before getting to the JSON. Fails all my short tool-call configs. Reserve this model for reasoning workloads — math, logic, code-reasoning where the thinking-out-loud is the value.
If you do use it for reasoning, set max_tokens ≥ 1000 to accommodate the reasoning preamble.
⚠ Gemma-3-4B-it-4bit · NEEDS NATIVE SCHEMA
mlx-community/gemma-3-4b-it-4bit · head_dim 256 · 34 layers
Gemma uses its own tool-call convention: {"tool":"<name>","query":"..."} wrapped in a ```tool code fence. Forcing a different schema (like my {"tool":"web_search", "args":{...}}) is a misuse — Gemma will use its own format and my grader will flag it as “wrong.”
I haven’t yet benchmarked Gemma with its native format. That’s a v1 task. For now: if you want a Gemma-flavored result, follow Gemma’s tool-call convention from its model card.
Note: head_dim=256 means yzamari recomputes the Lloyd-Max codebook at load time (logged inline). Costs a few seconds on first load.
Headline take-away across all six
There is no one-size-fits-all KV-quant config. Smaller models don’t need more buffer — they share the cliff position. Reasoning-tuned models need more tokens, not less buffer. Some models have their own tool-call conventions you have to use. The model card hasn’t been displaced by the leaderboard — it’s just been moved into the runtime config.
9. Reproducibility
Every finding above maps to a script in the repo. Clone and run:
git clone https://github.com/sathishksomasundaram/agentic-evals
cd agentic-evals
uv sync
uv run pre-commit install| Finding | Script | Command |
|---|---|---|
| Buffer dominates bit-width (§3) | experiments/exp001/yzamari_sweep.py | uv run agentic-evals exp-001 yzamari-sweep |
| Cliff is sharp (§4) | experiments/exp001/cliff_fine_sweep.py | uv run agentic-evals exp-001 cliff-fine-sweep |
| Hallucination below cliff (§5) | (same as §4 — examine the output field for buf=973 row) | as above |
| Compression > baseline (§7) | experiments/exp001/replication_buf_cliff.py | uv run agentic-evals exp-001 replication-buf-cliff |
| Cross-model patterns (§6) | experiments/exp001/v0_runner.py + experiments/exp001/cliff_per_model.py | for m in <models>; do uv run agentic-evals exp-001 v0-runner --model $m; done |
Plus:
- The original NumPy reference implementation of TurboQuant (provided by a project collaborator) used to validate that the rachittshah port’s algorithm matches the paper. Worth checking if you implement your own port.
- The MLX port I settled on after evaluating three candidates: yzamari/mlx-turboquant. Has the buffer parameter, the Metal kernels, and the honest disclosure that needle-retrieval fails on compressed tokens. The right choice on Apple Silicon as of May 2026.
One bug I hit and worked around: yzamari’s port crashes when you load multiple different models in the same Python process — ImportError: cannot import name 'turboquant_value_weighted_sum_metal'. Workaround: run each model in its own uv run invocation via the OMB_V0_MODEL env var. Cheap fix. Worth filing upstream.
The narrative thread tying it all together is in the exp-001 README. Every spike’s full report (with output transcripts, timing, memory) is in the spike reports. The v0 leaderboard data is in leaderboard.csv and raw-results.jsonl.
Credits
This entire finding stands on someone else’s work. yzamari authored the MLX port yzamari/mlx-turboquant that every measurement in this post runs on. More importantly, the buffer_size concept at the very heart of this post — keeping the most recent N tokens uncompressed while quantizing the rest — is the production-shaped idea his port contributes on top of the TurboQuant paper. The buffer-size cliff is only observable because his implementation exposes that knob. His honest disclosure that needle-retrieval degrades on compressed tokens is also what sent me looking for the cliff in the first place. Thank you, yzamari — this work is built directly on yours.
Underneath the port, the TurboQuant algorithm itself is from Google Research — Zandieh, Daliri, Hadian, and Mirrokni (arXiv:2504.19874, April 2025).
10. What this is part of
This post is the first finding in something I’m building: an open, proof-first validation platform for agentic capabilities of local open-weight models. The ecosystem is loud with claims — free models that “match GPT-4,” tuning tricks that are “lossless,” frameworks that are “5x faster.” Most of it is never independently tested. My goal is to be the place where those claims get validated with proof: reproducible code, captured data, and — where it helps — the entire testing harness, free to download and run.
The goal is per-capability deployment recommendations — “for tool-calling on Apple Silicon at the 7B class, use these models with these configs” — rather than a single holistic leaderboard. Existing leaderboards rank models on aggregate metrics. I want to answer the practical deployment question: which model + which inference config for which task — and prove it.
The scope is deliberate: local, privacy-first AI on the laptops developers actually own — no datacenter, no NVIDIA. This post is Apple Silicon + MLX. The niche is narrow on purpose; depth and honest proof beat breadth.
Roadmap items:
- More capabilities — routing, classification, code, RAG, multi-modal, beyond tool-calling
- The next backend, same niche — a consumer Windows laptop with no discrete GPU (llama.cpp / Ollama / LM Studio), to test which of these findings are portable behaviour and which are Apple-MLX-only
- Per-model native tool-call conventions (Gemma surprised me; others probably do too)
- Statistical replication (most cells are n=1 today; need n≥3 for production-grade claims)
- A dashboard (results are in JSONL/CSV today; visualization layer is v2 work)
If you’ve measured similar quantities on hardware or model families I haven’t covered, I’d love a contribution. The runner is parameterized and the data format is structured. And if you’ve found cases where these findings don’t replicate on your hardware or workload — that’s the most valuable feedback I can get. The whole point of publishing the harness is so you can prove me wrong.
That’s the standard I’m holding myself to: free, local, secure AI for all — and every claim backed by proof you can run yourself.
Coming next in this series
This finding opened more questions than it closed. Posts I’m working on next (links go live as they publish):
- Part 2 — Does the cliff move with model size? Per-model cliff localization across Llama-3.2, Phi-4-mini, and friends. (coming soon)
- Part 3 — When compression beats full precision. The result that surprised me most: on dilute long contexts, lossy KV compression can make a model more reliable, not less. (coming soon)
- Part 4 — The harness, not the model. Why I think a good harness around a 7B model beats a frontier model for 90% of real work — and how the local assistant I’m building rests on that bet. (coming soon)
If that’s the kind of thing you want in your feed, follow along:
- GitHub Discussions —
agentic-evalsrepo (goes live when the repo is public) — ask questions, share results, challenge findings - LinkedIn — Connect on LinkedIn — where I post each new finding
(A newsletter is on the roadmap — once enough of you tell me it’d be worth your inbox. For now, GitHub and LinkedIn are home.)
Reproduce it yourself
The whole point is that you don’t take my word for it:
git clone https://github.com/sathishksomasundaram/agentic-evals
cd agentic-evals
uv sync && uv run pre-commit install
uv run agentic-evals exp-001 cliff-fine-sweep # reproduce the cliff in §4- Full reproducibility table → §9 above
- Glossary of every term I use → GLOSSARY.md
- The local-first agent this all feeds → (coming soon)
Found a case where it doesn’t replicate on your hardware? That’s the most useful thing you can send me — it’s how we both get to the truth.
This dataset came out of 9 spikes, 1 multi-model benchmark run, 2 occasions where I had to correct my own earlier claims, and 1 surprising result that replicated cleanly. The full spike reports document the path honestly — including the times I was wrong and what changed my mind. That trail is part of the proof.
Repository link, license, and contribution guide coming soon. Until then: every finding above is reproducible from the code paths cited.
Appendix
Notation. The § symbol — the “section sign” — marks an internal cross-reference in this post; e.g. §4 jumps to Section 4.
Built on yzamari/mlx-turboquant. The buffer_size knob this entire post turns on comes from yzamari’s MLX port, yzamari/mlx-turboquant — the implementation every measurement here runs on. (Full acknowledgement in Credits above.)
Quotes status. The blog’s whole premise is “proof, not hype” — so no fabricated or misattributed quotes. The post uses exactly one quote, and it’s verified:
§5 (hallucination) — VERIFIED ✅. Andrej Karpathy: “…in some sense, hallucination is all LLMs do. They are dream machines.” Wording confirmed verbatim against the primary source x.com/karpathy/status/1733299213503787018 (Dec 9, 2023) — the draft uses a clean mid-sentence excerpt. One of the most-cited LLM quotes; ties directly to the finding.
Principle: a verified quote with a link, or no quote. Never a guess.